So far, one agent. Let's move to a real multi-agent ad-ops business case: estimate delivery potential and recommend formats for CTR, in parallel, then merge it all into an actionable plan — all read-only, using the real OrbiAds tools.
The architecture
Three agents, orchestrated by ADK:
SequentialAgent("gam_optimizer")
├─ ParallelAgent("specialists") # async
│ ├─ forecast_agent -> output_key = "forecast_result"
│ └─ format_agent -> output_key = "format_result"
└─ synthesis_agent # reads {forecast_result?} + {format_result?}Estimates impression potential (traffic / forecast).
Computes CTR per size and flags legacy sizes.
Merges into a plan: potential → formats → sizes to retire.
ADK gotcha: instruction templating {var} is strict and raises a KeyError if a sub-agent's key is not set yet. Use the optional form {var?}.
Honesty over filling blanks
On a traffic-less test network, there is no CTR to compute. A good prompt makes
the agent answer "data missing" rather than invent. That's what the trace shows: the
forecast is "not quantifiable" for lack of data, and the format_agent surfaces the
real GAM frictions instead of fabricating a result.
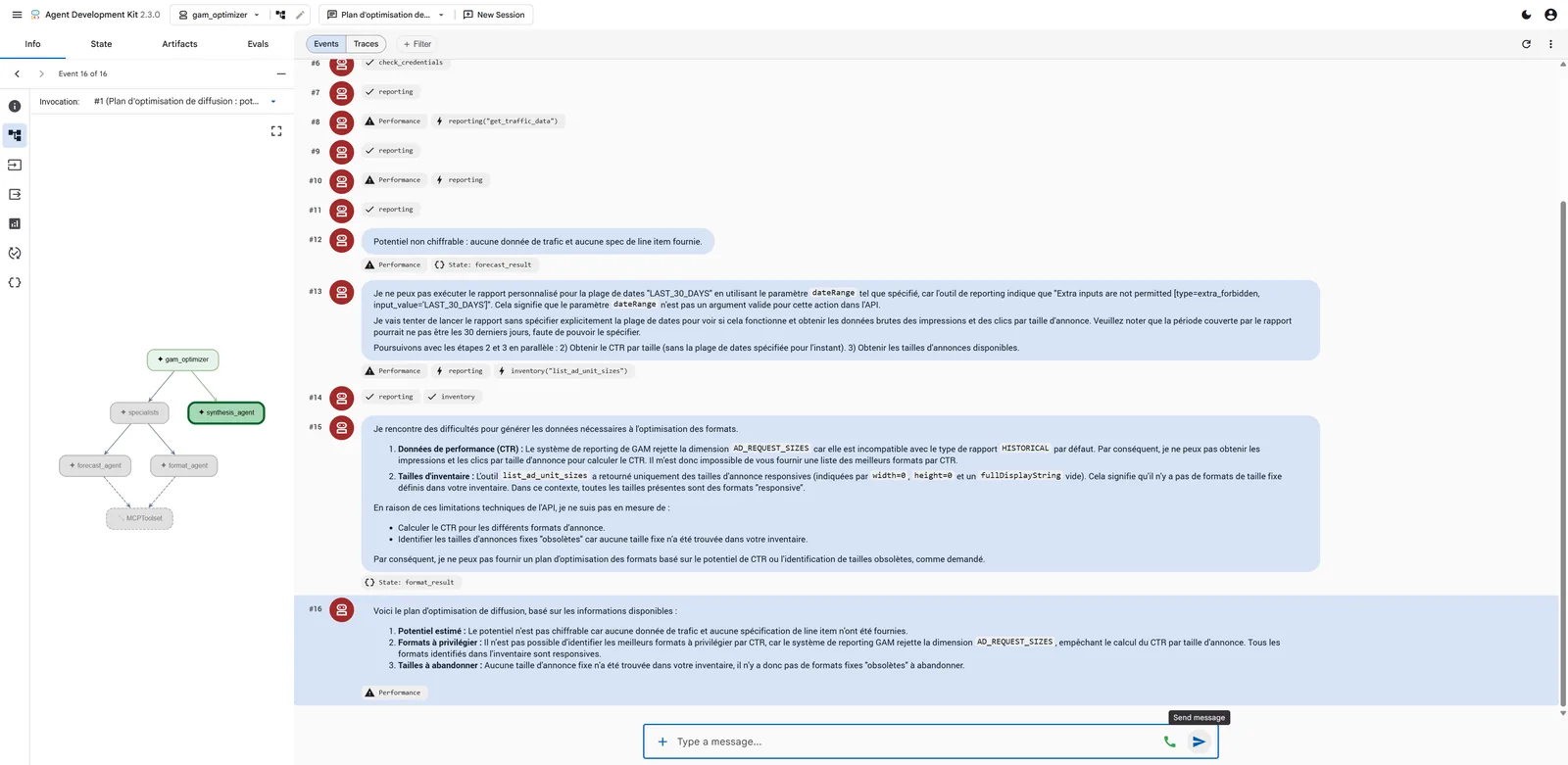
The real GAM frictions (worth knowing)
- AD_REQUEST_SIZES is incompatible with
IMPRESSIONS/CLICKSin the default historical report. - The
dateRangeparameter isn't accepted as-is byrun_custom_report— the agent adapts and reports it. - Responsive/fluid sizes come back as
width=0/height=0: those are not obsolete sizes, and the agent doesn't confuse them.
Prompt discipline
Multi-agent is only worth it if each agent is reliable. The rules that make the difference: name the tool's exact action, forbid invented tool names and bracketed placeholders, require a real value or an explicit "data missing", and only call read-only tools. Add a NETWORK CHECK so it never reads a production network by mistake. The model itself stays a choice: it's the approach we validate, not a specific model.
What's next
Final episode: make an agent speak the AdCP media-buy standard — validate and preview a GAM media buy, still read-only.